
Experts Say AI Copyright Cases Could Have Negative Impact on Academic Research
Deven Desai and Mark Riedl have seen the signs for a while.
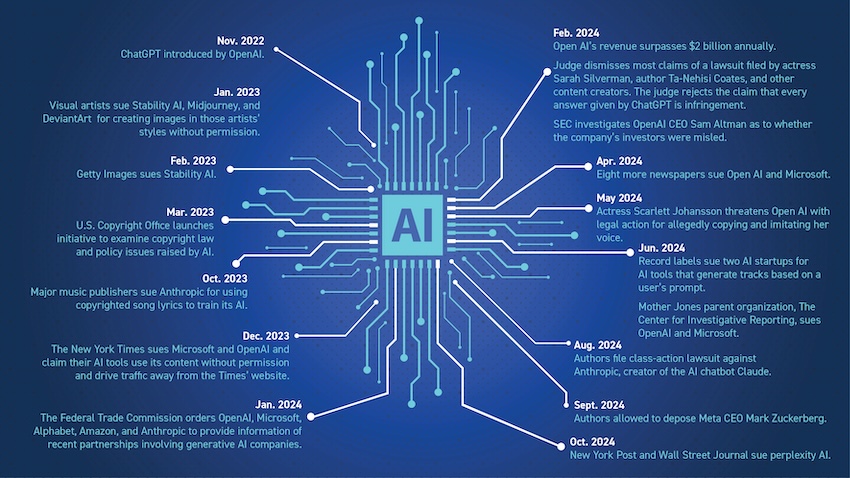
Two years since OpenAI introduced ChatGPT, dozens of lawsuits have been filed alleging technology companies have infringed copyright by using published works to train artificial intelligence (AI) models.
Academic AI research efforts could be significantly hindered if courts rule in the plaintiffs' favor.
Desai and Riedl are Georgia Tech researchers raising awareness about how these court rulings could force academic researchers to construct new AI models with limited training data. The two collaborated on a benchmark academic paper that examines the landscape of the ethical issues surrounding AI and copyright in industry and academic spaces.
“There are scenarios where courts may overreact to having a book corpus on your computer, and you didn’t pay for it,” Riedl said. “If you trained a model for an academic paper, as my students often do, that’s not a problem right now. The courts could deem training is not fair use. That would have huge implications for academia.
“We want academics to be free to do their research without fear of repercussions in the marketplace because they’re not competing in the marketplace,” Riedl said.
Desai is the Sue and John Stanton Professor of Business Law and Ethics at the Scheller College of Business. He researches how business interests and new technology shape privacy, intellectual property, and competition law. Riedl is a professor at the College of Computing’s School of Interactive Computing, researching human-centered AI, generative AI, explainable AI, and gaming AI.
Their paper, Between Copyright and Computer Science: The Law and Ethics of Generative AI, was published in the Northwestern Journal of Technology and Intellectual Property on Monday.
Desai and Riedl say they want to offer solutions that balance the interests of various stakeholders. But that requires compromise from all sides.
Researchers should accept they may have to pay for the data they use to train AI models. Content creators, on the other hand, should receive compensation, but they may need to accept less money to ensure data remains affordable for academic researchers to acquire.
Who Benefits?
The doctrine of fair use is at the center of every copyright debate. According to the U.S. Copyright Office, fair use permits the unlicensed use of copyright-protected works in certain circumstances, such as distributing information for the public good, including teaching and research.
Fair use is often challenged when one or more parties profit from published works without compensating the authors.
Any original published content, including a personal website on the internet, is protected by copyright. However, copyrighted material is republished on websites or posted on social media innumerable times every day without the consent of the original authors.

In most cases, it’s unlikely copyright violators gained financially from their infringement.
But Desai said business-to-business cases are different. The New York Times is one of many daily newspapers and media companies that have sued OpenAI for using its content as training data. Microsoft is also a defendant in The New York Times’ suit because it invested billions of dollars into OpenAI’s development of AI tools like ChatGPT.
“You can take a copyrighted photo and put it in your Twitter post or whatever you want,” Desai said. “That’s probably annoying to the owner. Economically, they probably wanted to be paid. But that’s not business to business. What’s happening with Open AI and The New York Times is business to business. That’s big money.”
OpenAI started as a nonprofit dedicated to the safe development of artificial general intelligence (AGI) — AI that, in theory, can rival human thinking and possess autonomy.
These AI models would require massive amounts of data and expensive supercomputers to process that data. OpenAI could not raise enough money to afford such resources, so it created a for-profit arm controlled by its parent nonprofit.
Desai, Riedl, and many others argue that OpenAI ceased its research mission for the public good and began developing consumer products.
“If you’re doing basic research that you’re not releasing to the world, it doesn’t matter if every so often it plagiarizes The New York Times,” Riedl said. “No one is economically benefitting from that. When they became a for-profit and produced a product, now they were making money from plagiarized text.”
OpenAI’s for-profit arm is valued at $80 billion, but content creators have not received a dime since the company has scraped massive amounts of copyrighted material as training data.
The New York Times has posted warnings on its sites that its content cannot be used to train AI models. Many other websites offer a robot.txt file that contains instructions for bots about which pages can and cannot be accessed.
Neither of these measures are legally binding and are often ignored.
Solutions
Desai and Riedl offer a few options for companies to show good faith in rectifying the situation.
- Spend the money. Desai says Open AI and Microsoft could have afforded its training data and avoided the hassle of legal consequences.
“If you do the math on the costs to buy the books and copy them, they could have paid for them,” he said. “It would’ve been a multi-million dollar investment, but they’re a multi-billion dollar company.”
- Be selective. Models can be trained on randomly selected texts from published works, allowing the model to understand the writing style without plagiarizing.
“I don’t need the entire text of War and Peace,” Desai said. “To capture the way authors express themselves, I might only need a hundred pages. I’ve also reduced the chance that my model will cough up entire texts.”
- Leverage libraries. The authors agree libraries could serve as an ideal middle ground as a place to store published works and compensate authors for access to those works, though the amount may be less than desired.
“Most of the objections you could raise are taken care of,” Desai said. “They are legitimate access copies that are secure. You get access to only as much as you need. Libraries at universities have already become schools of information.”
Desai and Riedl hope the legal action taken by publications like The New York Times will send a message to companies that develop AI tools to pump the breaks. If they don’t, researchers uninterested in profit could pay the steepest price.
The authors say it’s not a new problem but is reaching a boiling point.
“In the history of copyright, there are ways that society has dealt with the problem of compensating creators and technology that copies or reduces your ability to extract money from your creation,” Desai said. “We wanted to point out there’s a way to get there.”



As computing revolutionizes research in science and engineering disciplines and drives industry innovation, Georgia Tech leads the way, ranking as a top-tier destination for undergraduate computer science (CS) education. Read more about the college's commitment:… https://t.co/9e5udNwuuD pic.twitter.com/MZ6KU9gpF3
— Georgia Tech Computing (@gtcomputing) September 24, 2024