
Episode of 'Friends' Inspires New Tool that Provides Human-like Perception to MLLMs
For Jitesh Jain, conducting a simple experiment while watching one of his favorite TV series became the genesis of a paper accepted into a prestigious computer vision conference.
Jain is the creator of VCoder, a new tool that enhances the visual perception capabilities of multimodal large language models (MLLMs). Jain said MLLMs like GPT-4 with vision (GPT-4V) are prone to miss obscure objects that blend in with other objects in an image.
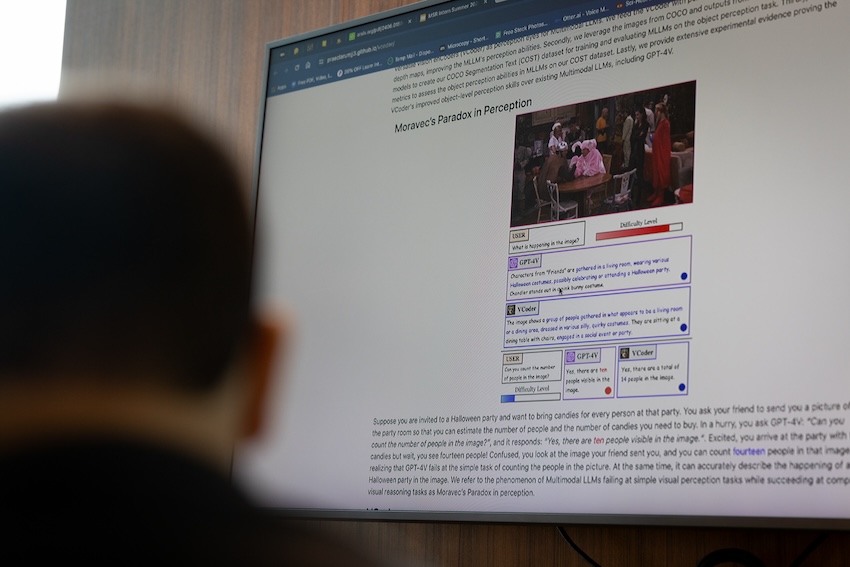
Jain paused his TV as he watched The One with the Halloween Party episode of the popular TV Series Friends.
Chandler stood out the most in a pink bunny costume while holding hands with Ross in a potato costume. As the two prepared for an arm-wrestling match with Joey and Phoebe, multiple groups socialized behind them.
Jain wondered how accurate GPT-4V would be if he prompted it to describe everything happening in this image.
“I watch a lot of TV series, so I frequently think about ways to leverage or include some aspects of those into my work,” said Jain, a Ph.D. student in the School of Interactive Computing. “The scene was very cluttered, so I thought, what questions could I ask GPT-4 about this show.”
On the surface, the generative AI chatbot knew much about the image. It knew which show and episode it was from and recognized the man in the bunny costume as Chandler. It knew the main characters were hosting a Halloween party.
But when Jain prompted the chatbot to count the number of people in the image, he discovered that GPT-4V and its open-source counterparts fell short of performing the simplest task.
It answered 10 when the correct answer was 14. In the right corner of the image, there is a group of people standing in front of a dark curtain that GPT-4V had missed.
AI Paradox
Jain had a theory — the MLLMs had not been trained for the object perception task and did not have the necessary information to perceive the objects in the foreground and background.
“We started testing it with different pictures, and GPT-4V kept underperforming,” Jain said. “The key takeaway is that it couldn’t do a simple task such as counting the people in the scene, but it knew complex information such as what was happening and who the characters were. This phenomenon is Moravec’s Paradox in Perception — the MLLMs visually reason about complex questions but fail at simple object perception tasks like counting.”
Jain said he has worked on image segmentation tools for the past two years. That includes when he was a research intern at Picsart AI under his now Ph.D. advisor Humphrey Shi, an associate professor in the School of Interactive Computing.
The core idea behind VCoder is to act as a perceptive eye for the MLLM, using segmentation and depth maps obtained through established computer vision frameworks with minimal training costs. The tool also proposes evaluation metrics for object perception tasks like counting and ordering.
Its training and evaluation set consists of images from Common Objects in Context (COCO), a widely used object perception dataset. Associate Professor James Hays from the School of Interactive Computing was one of the academic collaborators who worked with Microsoft to create COCO.
Improving MLLMs
Though VCoder didn’t know which show the image was from, it accurately described everything, including the number of people. It showed as much as 10% more accuracy than its nearest competitor.
It could also identify the order of objects in a scene.
Jain designed VCoder to integrate easily with existing MLLMs. He said augmenting MLLMs with VCoder leads to an MLLM with sound general reasoning and object perception capabilities.
However, he added he was unsure if integration would happen because companies like Open AI, which created GPT-4V, may overlook it.
“There’s no way to know if they will integrate since GPT-4V is a closed model, and their main motivation is to make a product useful to consumers in general,” he said. “They often ignore these small issues.”
Jain’s paper was accepted into the Institute of Electrical and Electronics Engineers’ 2024 Conference on Computer Vision and Pattern Recognition (CVPR), occurring June 17-21 in Seattle. CVPR is the highest-ranked conference in computer vision according to Google Scholar.



As computing revolutionizes research in science and engineering disciplines and drives industry innovation, Georgia Tech leads the way, ranking as a top-tier destination for undergraduate computer science (CS) education. Read more about the college's commitment:… https://t.co/9e5udNwuuD pic.twitter.com/MZ6KU9gpF3
— Georgia Tech Computing (@gtcomputing) September 24, 2024